Likes
On October 10, 2019, an article on the results of the research by Professor Weng Xuchu’s research group, was published on line in PLOS Biology, an internationally leading academic journal in the field of neuroscience with an SCI impact factor of 9.527 for five years. The article was entitled: “Development of neural specialization for print: Evidence for predictive coding in visual word recognition.” The research provides the preliminary evidence that specialized word processing relies on a predictive coding mechanism.
The research group is led Professor Weng Xuchu at the Institute for Brain Research and Rehabilitation, and the first author of this article is Dr. Zhao Jing from Hangzhou Normal University.
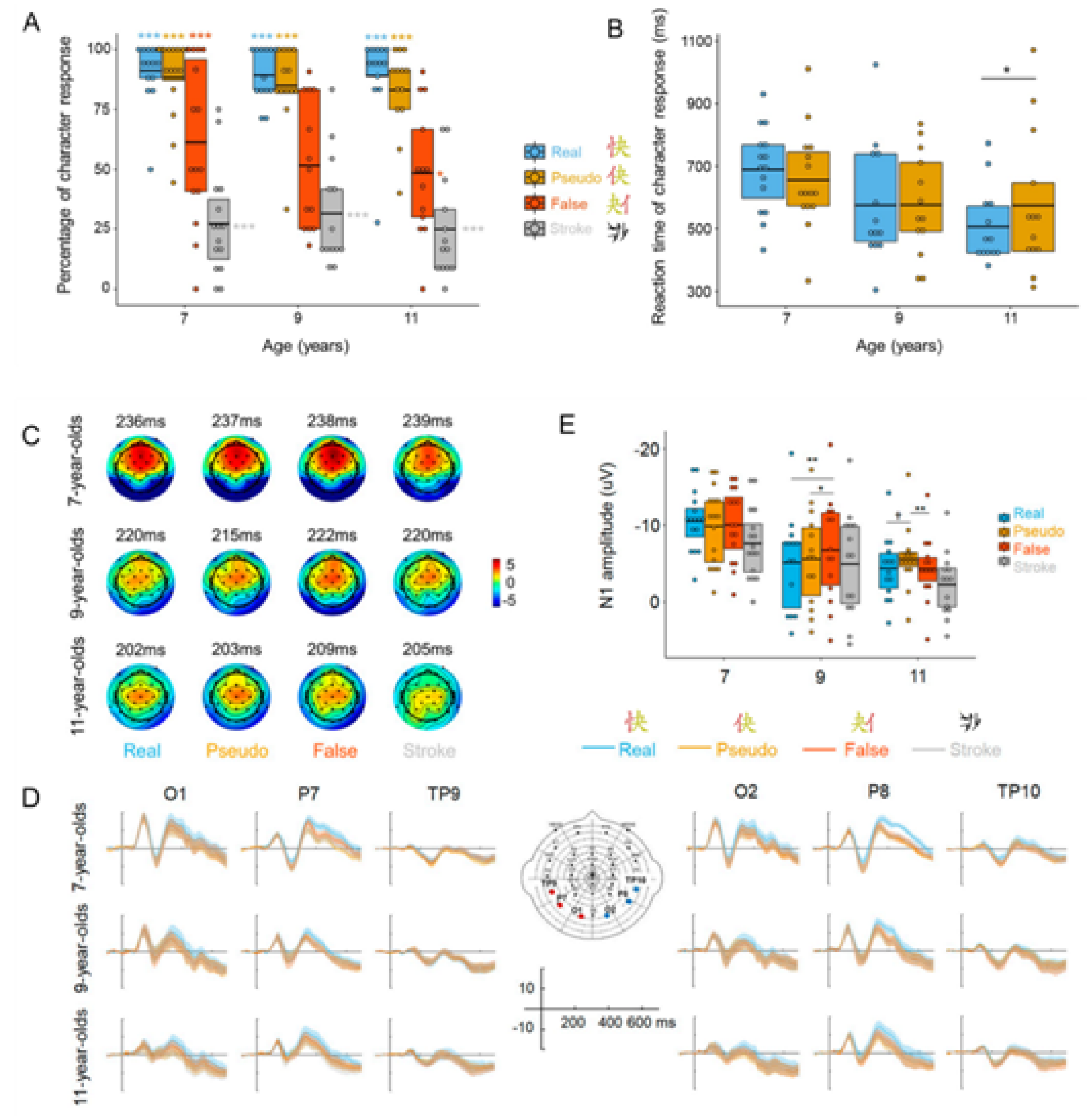
Text reading is not only a key method for modern humans to learn knowledge and exchange information, but also a basic skill for individual study, work, and life. A large amount of research in the field of cognitive neuroscience shows that there is specialized visual-orthographic processing in the brain to support humans to read text quickly and accurately, but how it works is still unknown. The research, with a cross-sectional study design, systematically investigated processes while learning to read, (1) children’s word processing mechanism, (2) 3 types of non-character stimuli (pseudo character, false character, stroke combination) (Fig. 1 A-B), (3) the development mode of N1 (N170) component (a reliable physiological measure for specialized word processing) (Fig. 1 C-E).
(Fig. 1A) Percentage of character response. Hit for real characters and false alarm for the other 3 stimulus types in the behavioral lexical decision task.
(Fig. 1B) Researchers used a content-irrelevant color-matching task with a short duration of stimulus presentation (Fig. 1B) to target nonstrategic automatic predictions
(Fig. 1C) Topographic maps at N1 peaks of 4 types of stimuli on P7 electrode across 3 age groups (see S8 Table and S4 Text for detailed results of N1 peak latency).
(Fig. 1D) Grand ERP wave forms of 4 types of stimuli at occipitotemporal electrodes in each group (left panel: O1/P7/TP9 electrodes on the left hemisphere; right panel: O2/P8/TP10 electrodes on the right hemisphere). Error bands are 95% nonparametric CIs (2,000 bootstraps)
(Fig. 1E) Box plots of mean N1 amplitudes for the 4 stimulus types at left occipitotemporal electrodes in each group.
Taken together, researchers observed a stronger N1 response to stimuli with lower orthographic regularity (less character-like) but only when efficiency in lexical classifying for these stimuli was reduced (high prediction error) at a certain age, as indicated by stronger N1 responses to false characters in the 9-year-olds and to pseudo characters in the 11-year-olds, respectively. They observed a robust interaction between a stimulus’ orthographic regularity (bottom-up input) and children’s lexical classification ability (top-down prediction): electroencephalogram (EEG) N1 responses were stronger to lower-regularity stimuli, but only in children who were less efficient in lexically classifying these stimuli (high prediction error).
The present findings resolve the controversy in understanding the mechanisms of reading skill acquisition and offer very strong support for predictive coding as the underlying mechanism during the development of neural specialization for print.
Translated by Huang Mengxiao
Proofread by Edwin Baak
Reviewed by Li Jianru
What to read next: